Головний висновок стосується того, що видимість у ChatGPT неоднорідна. Ваш контент може спливати у швидких відповідях, але зникати, щойно користувач ставить складніше питання, — і навпаки. Бути присутнім потрібно на обох рівнях, а це залежить від того, чи здатні ваші сторінки, документація та згадки на сторонніх ресурсах виринати в тих численних дрібних пошуках, які модель здійснює перед відповіддю.
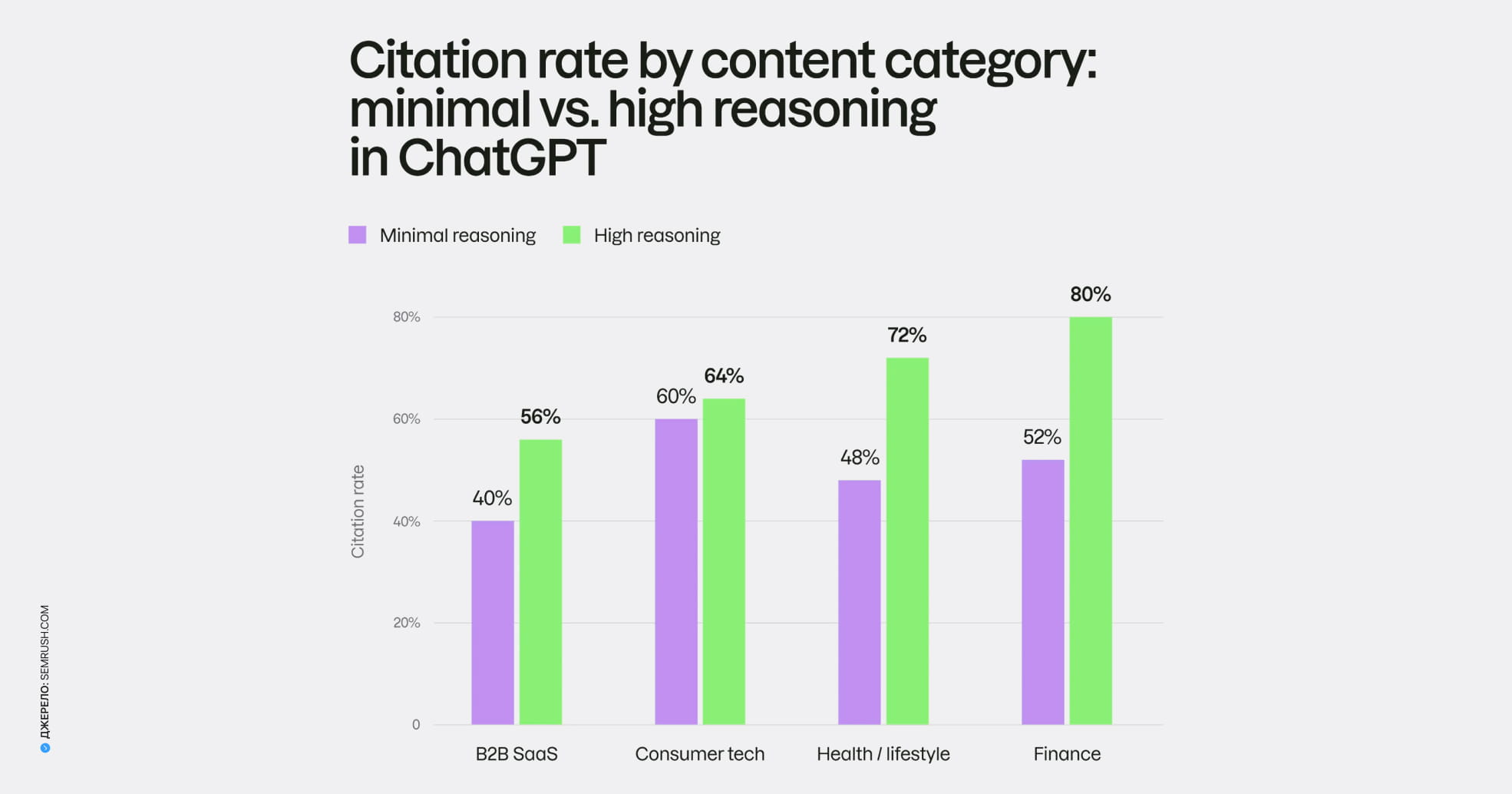
Оскільки глибокий режим тягнеться до першоджерел і офіційної документації, вагу набирає якість і повнота власного контенту. Детальні сторінки з характеристиками, чіткі описи, довідкові розділи — усе це підвищує шанс потрапити в цитування. Фундамент тут той самий: докладне наповнення сайту контентом і системне SEO-просування, що робить ваш ресурс придатним джерелом. Про те, які матеріали асистенти цитують охочіше, ми писали в окремому розборі.
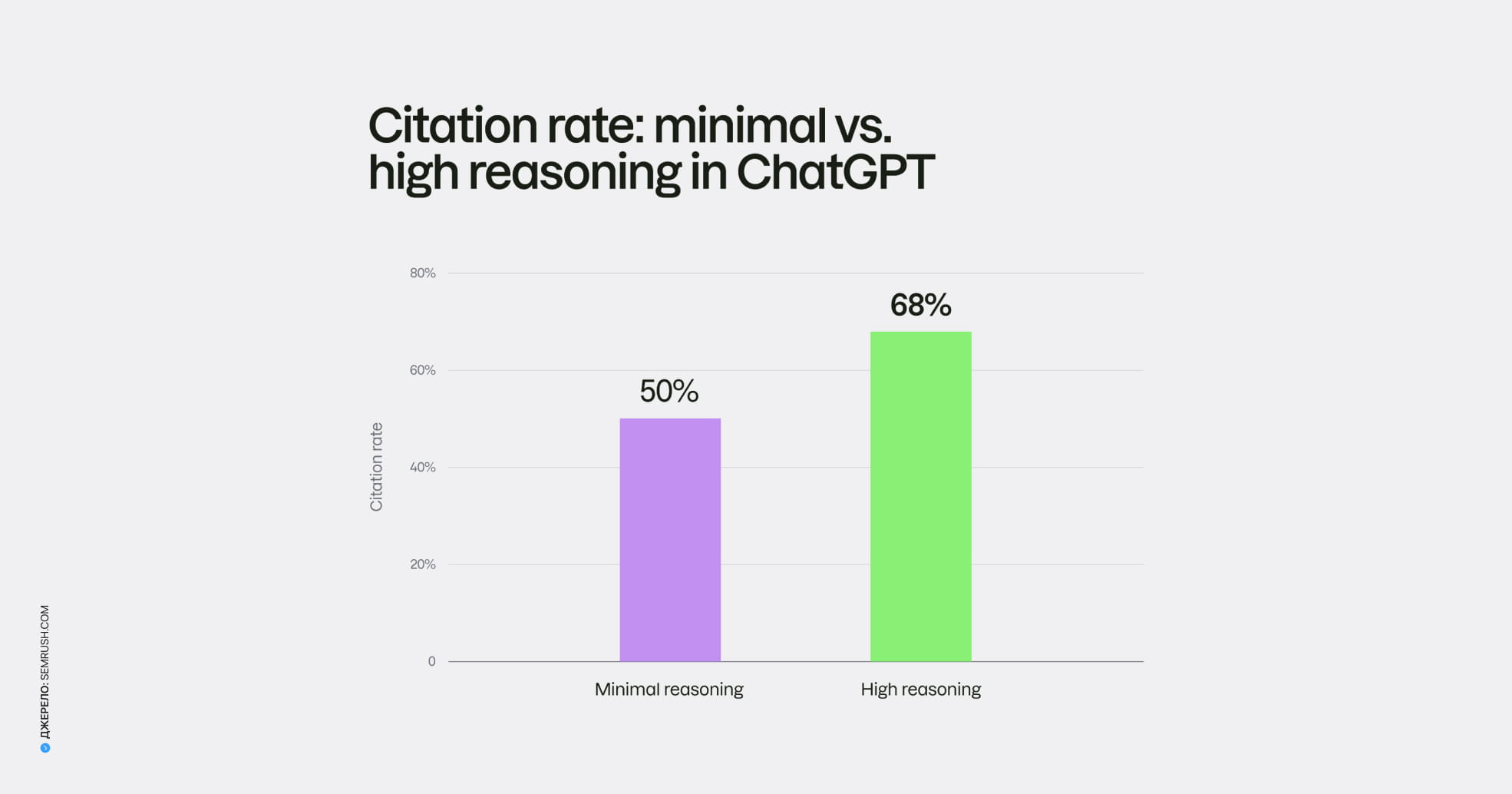
Наступне спостереження перегукується з тим, про що ми вже розповідали. Це дослідження стало ще одним підтвердженням, що ШІ-видимість — річ нестабільна. Раніше з’ясувалося, що увімкнений пошук змінює 80% товарних рекомендацій ChatGPT, а тепер бачимо, що навіть режим міркування перетасовує джерела на три чверті. Ставити все на одну ШІ-платформу чи один режим ризиковано.
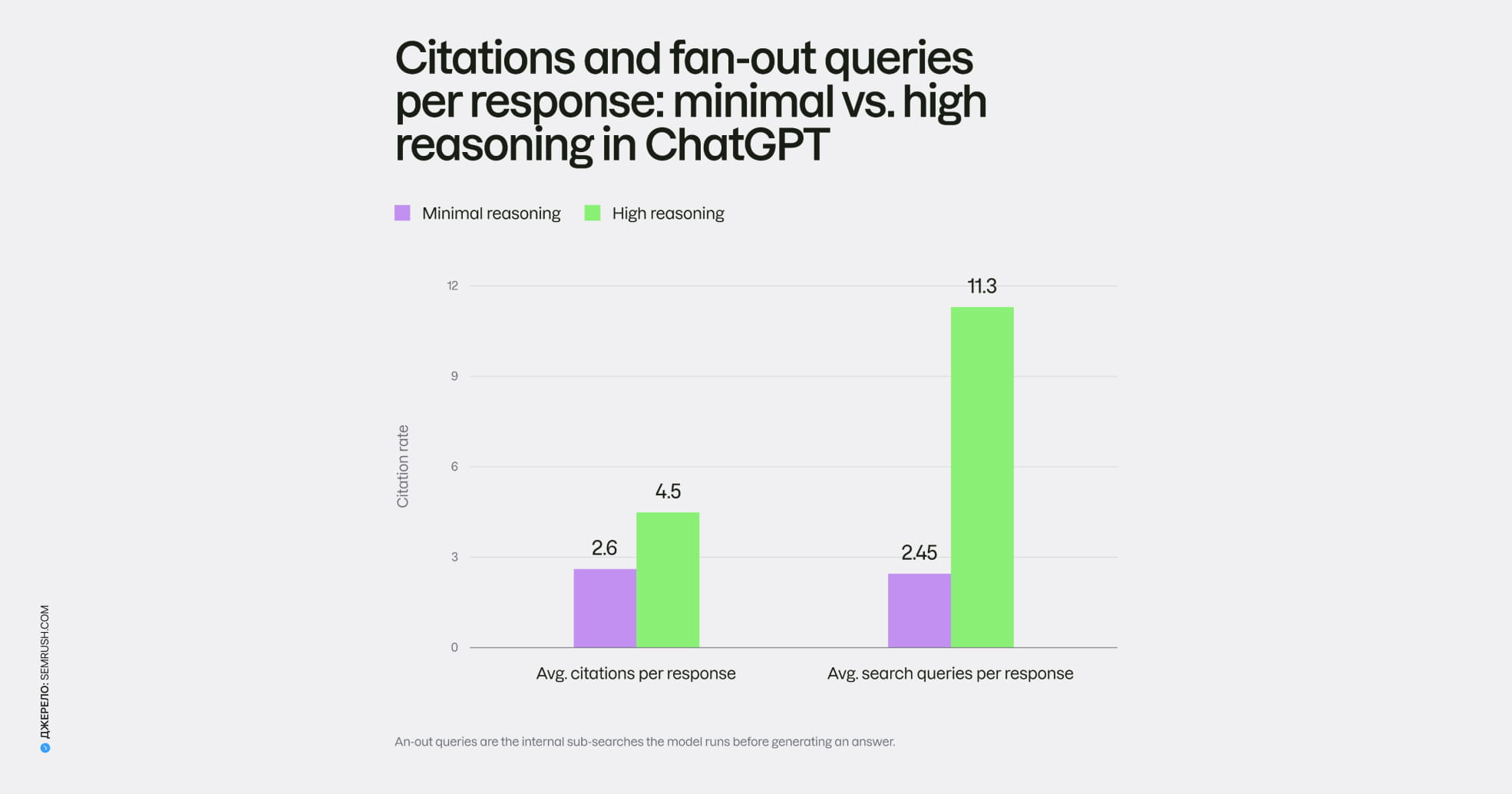
Окремо варто сказати про порівняльний контент. Оскільки саме на етапі порівняння модель запускає лавину підзапитів про ціни, інтеграції та безпеку, бізнесу є сенс мати окремі, добре опрацьовані сторінки під кожен із цих аспектів. Що детальніше ви розкриваєте порівняльні характеристики, то більше точок дотику даєте моделі, що збирає відповідь із дрібних частин.



Комментарии